
GlusterFS is an open-source, scalable, distributed file system designed to handle large amounts of data across multiple storage servers. Developed by Gluster Inc. (later acquired by Red Hat), GlusterFS is highly flexible and can be used for a variety of storage scenarios, including cloud storage, media streaming, and big data analytics.
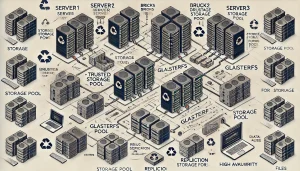
glusterfs architecture
Key Features of GlusterFS
Scalability:
GlusterFS allows you to scale out by simply adding more servers (nodes) to the cluster. This enables it to handle petabytes of data seamlessly.Distributed Storage:
Data is spread across multiple nodes, enabling efficient utilization of storage resources and avoiding bottlenecks.High Availability:
It offers redundancy and fault tolerance by replicating data across multiple nodes. If one node fails, the system continues functioning without data loss.Elasticity:
You can add or remove storage nodes without disrupting the system, making it suitable for dynamic environments.POSIX-Compliant:
GlusterFS supports standard POSIX file system operations, allowing easy integration with existing applications.Software-Defined Storage:
Being software-based, GlusterFS eliminates the need for specialized hardware, reducing costs and enhancing flexibility.Geo-Replication:
Data can be replicated across geographically distributed data centers for disaster recovery and global availability.Protocol Support:
GlusterFS supports various protocols such as NFS, SMB/CIFS, and Object Storage (via the S3 API), making it versatile for different use cases.Self-Healing:
In case of node or disk failure, GlusterFS automatically repairs and synchronizes data when the failed components are restored.Ease of Management:
GlusterFS comes with a command-line interface and tools for easy deployment and monitoring of storage clusters.
Common Use Cases
- Cloud Storage: Ideal for private and hybrid cloud setups.
- Media and Content Delivery: For storing and streaming large multimedia files.
- Big Data Analytics: Suitable for storing and processing large datasets.
- Backup and Archiving: For maintaining multiple copies of critical data.
- Virtualization and Containers: Can be used as a storage backend for virtual machines and containerized applications.
Architecture Overview
GlusterFS organizes storage into volumes, which are logical collections of bricks (the basic unit of storage in GlusterFS). These bricks are directories on the underlying storage servers. Data distribution and redundancy are configured at the volume level, depending on the use case (e.g., distributed, replicated, or striped volumes).
Benefits
- Cost-effective due to its software-defined nature.
- High flexibility and performance for varied workloads.
- Vendor-neutral and open-source, providing transparency and community support.